綺麗なコードを書くためのマイナーな自己ルール 5 選

この記事は2024/02/02に作成されました。
IT エンジニアで「コードは美しく書くべき」という教訓に異を唱える人は少ないでしょう。
美しいコードはよく整頓された部屋と一緒です。
ゆとりを持った空間は、新たな家具の導入、つまり機能追加をする場合、そのタスクを易しいものにします。無理やりスペースを作る作業はそもそも必要ありません。
心地よい空間にゴミが落ちていればすぐにそれを掃除したくなるでしょう。バグや場当たりいい加減なコードが混入していても、それを探し当てるのが簡単になります。
そして何より、美しいコード・部屋はずっとその環境で過ごしたいと思えます。IT エンジニアにおいて全てを一からやり直したくなる衝動は付き物ですが、それには大きなコストがかかります。
誤解を恐れつつ勢いで言えば、IT エンジニアは自分の部屋やデスクトップ、生活や肌が荒んでいても多少なら許されるフシがあります。
しかし、コードだけは美しさ溢れる聖域として守る使命があります。
なぜなら、コードは美しいから価値があるのではなく、
- ・改変しやすく
- ・バグを起こしづらく
- ・理解が用意で
- ・パフォーマンスに優れる
という条件を満たすと、おのずと美しくなるためです。
美術品と大きく違うのはこの点で、つまりコードは最終的なプロダクト・サービスのため美しくならざるを得ない存在なのです。
前置きが長くなりましたが、この記事は漠然と「もっと美しくコードを書くためには」という IT エンジニアに向けて、僕が普段努めている些細な Tips を紹介するものです。
同じような話題で検索してもあまり出てこない方法に絞りましたので、おそらく万事汎用なコードではないと思われます。
基本的には参画しているプロジェクト、または所属している会社のコーディングガイドラインに従う方が良いでしょう。僕一人が熟成させたルールよりも、多くの人を通って枯れたルールの方が信頼できます。
しかし、それでもなお何故か自分のコードが汚い気がする場合は、参考にしてみて下さい。
コメントを目次のように書く
コメントを目次のように書くとは、コードをパッと見たときに次のような状態になることです。
// 処理についての解説
実際の処理コード
// 処理についての解説
実際の処理コード
// 処理についての解説
実際の処理コード下記画像は実際に僕が個人的に開発している PHP クラスを「折りたたんだ」状態の表示です。
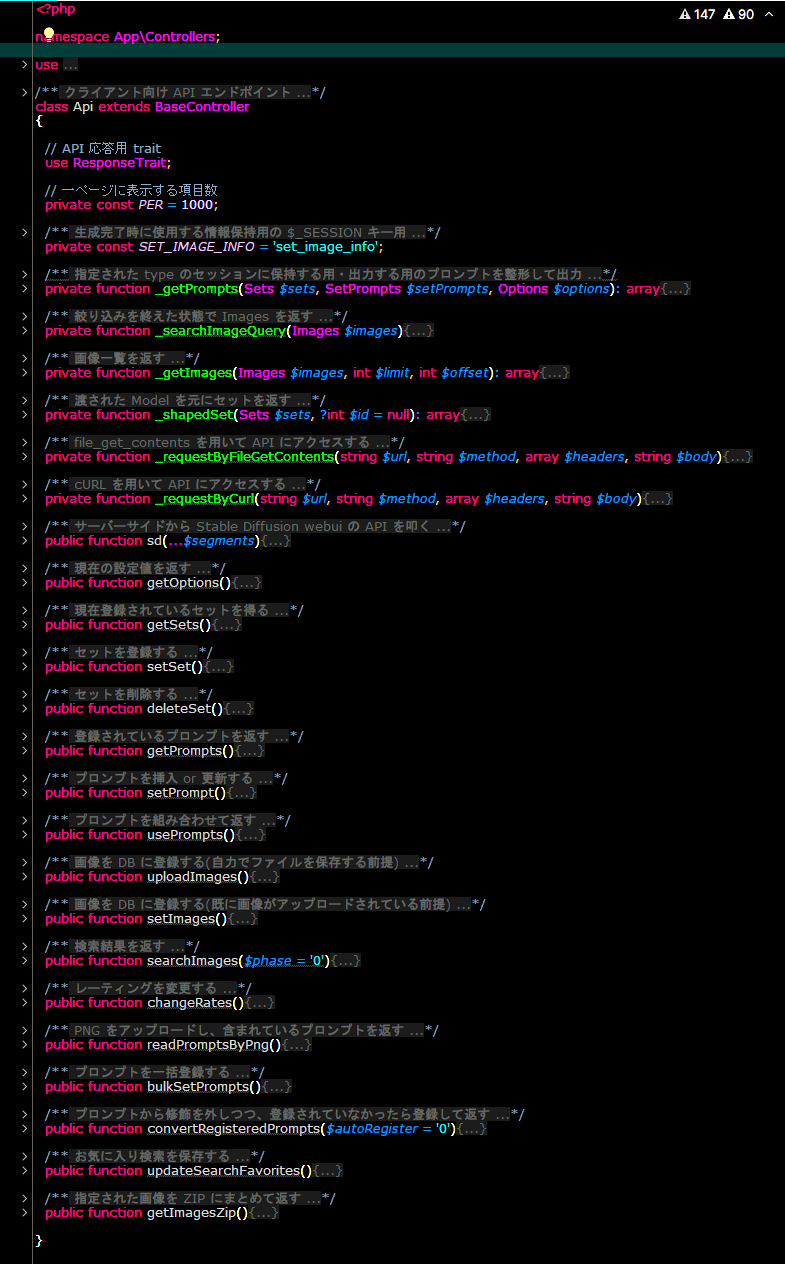
色は僕の趣味ですが、この並びを見ていると小説の見出しのようになっているのが分かるでしょうか。
僕はエディタでコードの折り畳みを使用した際、同じ階層に位置するコードを等間隔に並ぶように空行を挟みつつ、コメントと実際のコードが 2 セットになるようにしています。
こうすることで、後に改修のためコードを修正する際、目次コメントだけを読むことで目的のコードを探しやすくなるのです。
余談ですが、英語圏ではあまりコメントを過剰に書くべきでないとする意見があるようです。
理由は適切な変数名の命名や簡潔なコーディングをしていれば、そのコード自体がドキュメントになるのでわざわざコメントを書く必要がないとのことでした。
しかし僕は日本語話者なので、日本語に比べて英語で書かれている変数名などから直感的に意味をくみ取るのがワンテンポ遅れる気がします。
それよりかコード上に、
- ・英語があったらそれはプログラム部分
- ・日本語があったらそれはコメント・もしくはコンテンツ部分
と自動的に解釈してしまうので、日本語が書かれていたらそちらを先に読んでしまいます。
なので、少なくとも英語圏以外ではコメントは多く残したほうが有益だと考えています。
コメントは(必要であれば) Why も What も How も全部書く。ただし、一行目は What
先ほどの画像はよく見ると、処理部分だけでなくコメントも折りたたまれているのが分かると思います。
コメントはなるべく Why を書け、という教訓を耳にした方は多いと思いますが、僕は悩んだら全部書けばいいと考えます。かの有名なリーダブルコードでも同じような指摘があります。
ただし、僕は追加のルールとして、Why や What, How を混在させて書くときに、必ず Waht を一行目にするというルールを設けています。
なぜそうするかと言うと、使っているエディタにもよるのですが、コードの折り畳み機能を使用してコメントが折りたたまれたとき、一行目のみが表示されるケースに対応するためです。
プロダクトを改修したいがどこのコードを改修するべきか分からない場合、まずは全体を眺めて該当するコードを探すことから始める必要があります。
この時、エディタの折り畳み機能を使用すると一度に確認できるコード行数は増えますが、代わりに該当コードだと判別するための情報も折りたたまれてしまうかもしれません。
しかしこのとき、該当するコードが何であるか説明する What が一行目であれば折りたたみ状態でもコードを識別できる可能性が高くなるという利点があるのです。
1 回しか使用しない値は変数に代入しない
突然ですが、下記のようなコードを色々な所で見かけます(内容は適当です)。例は JavaScript ですが、どんな言語でも本当によく見かけます。
const foo = bar
.map(el => el.price + 30)
.filter(el => el.price < 100)
.reduce((result, current) => result.price * current.price);
return baz(foo);さて、僕が同じ処理を実装するなら、以下のように書きます。
return baz(bar
.map(el => el.price + 30)
.filter(el => el.price < 100)
.reduce((result, current) => result.price * current.price));最初の例では関数 baz に渡すための値として、bar を加工しているのですが、加工後の値を一旦 foo として定義しています。
それに対して、次の例では baz の引数部分で直接 bar を加工しているからです。
僕がこのようにする理由は二つあります。
まず一つ目は、一回しか使用されない変数はバグの原因になる可能性が高いと考えられるからです。変数にした時点で思わぬ変更処理が挟まる危険性があります。
最初の例では変数を定義してからすぐに目的の関数へ使用しているため問題が無いように思えるかもしれません。
しかし慎重に考えると、バグが発生するシナリオとして以下のようなものが想定されます。
- ・この部分と直接の関連は無いコードが return baz(foo); の直前に差し込まれやすくなる。その差し込んだコードが baz 変数に副作用を与える処理だった場合、バグが発生する。
- ・この後に続くコードで baz という同名の変数を初期化宣言無しで使用すると、思わぬ値が入ってくる。
実際の仕事でこれらバグが実際に発生したら、責任は後から差し込んだ人間の方にあるのかもしれません。
しかし、未然に防げるバグはなるべく減らした方が良いでしょう。
二つ目に、パフォーマンスの最適化というメリットが挙げられます。
最近の実行環境は優秀なので、使用しなくなった変数がメモリから破棄されるタイミングはずいぶん最適化されました。
しかし、関数の引数部分で直接加工した値を作って渡せば、そもそもその値を長く保持する必要はありません。実行環境は、引数として値を渡された関数が終了したらその場でメモリから該当データを削除できるのです。
これらのメリットから、僕は一回しか使用しない値はなるべく使用箇所で直接生成するようにしています。
ただし、多くの開発者が後者の書き方をしないのは、恐らく可読性の問題なのだと推察されます。
そんな時、僕はコメントを書くことで可読性を担保することが多いです。
return baz(bar
// .map が何をしているかの説明
.map(el => el.price + 30)
// filter が何をしているのかの説明
.filter(el => el.price < 100)
// reduce が何をしているのかの説明
.reduce((result, current) => result.price * current.price));このようにメソッドチェーンの間に説明を書くこともほとんどの言語で可能です。
また、加工処理があまりにも長大な場合はサブルーチン化も視野に入ってきます。
const calcuration(value) => value
.map(el => el.price + 30)
.filter(el => el.price < 100)
.reduce((result, current) => result.price * current.price);
return baz(calcuration(bar));
else は原則使用しない
あらゆる言語でお世話になる if ですが、僕はその用途は以下の二つに大別できると考えています。
- ・正常系・異常系の分岐
- ・それ以外の分岐
先に else を使用する例外の条件ですが、上記「それ以外の分岐」に当てはまる場合は else を使用するケースがあります。
正常系と異常系とは大雑把に説明すれば、「ある目的を完遂するまで最初から最後まで問題なく済む道のりが正常系、問題が発生してエラーとして以降の処理を止めるのが異常系」のようになるでしょうか。
開発するプロダクトに因るでしょうが、今僕の開発しているプロダクト内の if 文をザッと確認したところ、 9 割以上の if 文が前者に分類されました。つまり、ほとんどの if 文は「理想的な処理の流れを妨げる異常を検知するために使用される」ということになります。
「正常系・異常系の分岐」の場合 else 文がいらなくなる理由ですが、だいたいのシステムでは異常が発生した時点でその先の処理に進む必要がないからです。
例として、あるユーザーが日記を投稿するというサービスを考えてみましょう。
例えば日記のタイトルは必須なのに、本文だけユーザーが送信してきたとします。この場合、サーバー側でバリデーションに引っかかった場合はユーザーにエラーを返すと思いますが、その先にある日記の登録処理は行う必要がありません。
さらに、ユーザーの送信データが正当な場合も、複数のデータを登録する際にある一部の登録処理が失敗した場合も、以降の登録処理を行うメリットはありません。大抵の場合データの登録先には RDB などを使用するかと思いますが、トランザクションがサポートされているなら十中八九ロールバック機能を使用して全てのデータ登録を無かったことにするでしょう。
これらを簡単な疑似コードにしてみます。
begin();
// 記事の投稿を試みる
if ( ! $db->post->insert($_POST['title'] ?? '', $_POST['content'] ?? ''))
{
$db->rollback();
return response(500, '投稿に失敗しました');
}
// 記事のサムネイル投稿を試みる
if ( ! $db->postMetas->insertThumbnails($_POST['thumbnails']))
{
$db->rollback();
return response(500, '投稿に失敗しました');
}
// この時点で成功確定なので、 DB に変更を適用
$db->commit();
// 成功を返す
return response(200, '投稿に成功しました。');
このように、異常を検知したら即 retun で処理を中断する方法を「早期リターン」と呼んだりします。
この早期リターンを徹底すると、 else は自然と出番が無くなるのです。
ただし、直感通り if 文を使用すると、これとは逆に正常側を if ブロックの中に閉じ込めてしまうので、多重ネストに陥りがちなので注意が必要です。
begin();
// 記事の投稿を試みる
if ($db->post->insert($_POST['title'] ?? '', $_POST['content'] ?? ''))
{
// 記事のサムネイル投稿を試みる
if ($db->postMetas->insertThumbnails($_POST['thumbnails']))
{
// この時点で成功確定なので、 DB に変更を適用
$db->commit();
// 成功を返す
return response(200, '投稿に成功しました。');
}
// 記事のサムネイル投稿失敗
else
{
$db->rollback();
return response(500, '投稿に失敗しました');
}
}
// 記事の登録失敗
else
{
$db->rollback();
return response(500, '投稿に失敗しました');
}
}
// バリデーションエラー
else
{
return response(400, '必須項目が入力されていません');
}
このように、
- ・if の中に直接 if が現れる(間に for などが挟まっている場合はサブルーチン化など検討)
- ・else が登場する
ような場合は改善が必要だと考えられます。
さらに、実は「それ以外の分岐」側でも else を使用しないケースは多いです。なぜなら、この場合は if 文ではなく switch 文や三項演算子を使用する可能性もあるからです。
曖昧な表現になりますが、分岐が「正常系」と「異常系」でない場合、分岐先は「等価」な処理であることがほとんどでしょう。
例えば EC システムにおいて、税計算方法を DB から参照して価格だけ分岐させる場合は変数の定義に switch 文を使用できます。
もちろん if ~ else if ~ else で書くこともできますが、switch 文や三項演算子をよく使うのであれば else を目にする機会は更に減るでしょう。
キャメルケース・スネークケース・ケバブケースはプロジェクト単位では統一しない、動作する言語ごとに変える
基本的にはコーディングガイドラインで縛られているはずなので、それに従うのが大前提となります。
が、僕はこれら縛りが無い、もしくは多少自由にできる場合は動作する言語、または場によって命名規則を変えます。
具体的に、一般的な Web サイトを例に取ると、
- ・PHP, JavaScript: キャメルケース
- ・DB のテーブル、フィールド: スネークケース
- ・HTML, CSS, URL, ファイル名: ケバブケース
として混在させることが多いです。
理由としてはまず、その動作ヶ所によっては推奨されている命名規則以外では動作に問題が出る可能性があるためです。
例えば URL 上では大文字小文字が区別されないので、大文字を含む URL は動作こそするものの、全て小文字にした URL も同じ URL として認識されます。
次に、命名された変数を見るだけでどこで使われる変数か判断しやすくなるメリットも重要です。
通常はキャメルケースでコーディングする PHP でもいきなりスネークケースの変数を見つけたら、それが DB のフィールド名を指している変数だと分かる、といったメリットです。
ただし、これは一貫して上記の法則を適用していると確定しているプロジェクトでのみ活きるメリットです。
特に他人数で開発するプロジェクトでは、命名規則が任意で混在しているのか不注意で混在しているのか判断が難しいため、上記のようにするかは慎重に決めた方が良いでしょう。
通常、命名規則が統一されていないコードは汚いと感じるものですが、逆に一貫したルールが分かった上で混在されている命名規則は逆に整頓されて見えます。
Dart などでは既にディファクトスタンダートになっている、基本的にキャメルケース命名するものの、 private なメンバでは先頭に _ を付ける、と言ったルールと同じものと言えます。
プログラマー / N.Go
CodeIgniterやLaravel、Vue.jsといったフレームワークを用い、ECシステム、リアルタイム課金制生配信、掲示板ライクなSNSシステムなどのWebシステム制作に携わる。 プロジェクトによってはフロントエンドも一貫して請け負う。
