Ollama Desktop(GUI版)によるローカルLLMの利用

この記事は2025/08/04に作成されました。
Ollamaは各社や団体から提供されているLLM(大規模言語モデル)をローカル環境で動作させるための実行環境です。
例えば、Meta社が提供しているLlamaやGoogle社が提供しているGemmaなどをローカル環境で実行させることができます。
ローカル環境でLLMを動かすメリットはいくつか存在しますが、
- ・APIの使用料金が掛からない
- ・各社、各人固有のデータを投入して学習されても、外部に漏れることが(原理的には)ない
- ・他のシステムと組み合わせて動作させることが容易
- ・オフラインでも利用可能
辺りでしょう。もっとも、デメリットも多く、
- ・動作速度が動かしているPCの速度に大きく依存する
- ・動作させるためのスペック要求が極めて高い
- ・軽量なLLMを選ぶと精度がイマイチ
といったデメリットもあります。
実際に動作させると分かりますが、ある程度の精度はローカルで動作させるLLMでも出るようになってきてはいますが、オンラインで提供されているChatGPTやClaudeなどの精度に比べると若干、モノによっては相当精度が落ちます。
そのため、現状では趣味の域を出ない可能性もありますが、ローカルでLLMを動作させたい場合には、Ollamaなどを利用するのが現状では一般的になっています。
なお、ローカル環境でLLMを実行できるツールにはLM Studio、llama.cpp、text-generation-webuiなどもあります。これらの多くはコマンドライン操作が中心ですが、近年はGUI(グラフィカルユーザーインターフェイス)版も増えてきています。
Ollama Desktop(GUI版)を試してみる
2025年現在、Ollamaには公式GUI版である「Ollama Desktop」が提供されています。マウス操作で直感的に利用でき、従来通りAPI経由で他のシステムと連携することも可能です。
Ollama DesktopはWindows版、mac版、Linux版が提供されており、https://github.com/ollama/ollamaからダウンロードが可能です。
Windows版とmac版は通常通りのインストーラーとして提供されているため、ダウンロードして実行すればインストールが完了します。
このOllamaGUI版ですが、ほぼ見た目はChatGPTのGUI版と変わりません。ほとんど設定らしい設定も無く、自動的に設定されます。
唯一、コンテクストサイズをGUIから変更可能です。コンテクストサイズを変えると、必要なPCリソースが増えるので、適当なところで止めておく必要はありますが、コンテクストサイズを変えると、より大量のテキストを投入してLLMに処理して貰うことが可能です。
インストール直後は、LLM本体はダウンロードされていません。チャット画面右下のメニューから利用したいモデルを選択できますが、2025年8月時点ではLlamaなど一部のモデルは一覧に表示されません(今後の対応予定や、マシンスペックによる表示制御の可能性もあります)。執筆時点ではここにLlamaとかは出てきていないので、いずれ対応するのか、またはマシンスペックによっては出てこないのかは謎です。
選択したら、そのままプロンプトを記入して送信すると、LLMがダウンロードされます。容量はそれぞれのLLMごとに違うため、ダウンロード時間も異なりますが、ダウンロードが完了したら、プロンプトに対して応答があります。LLMがダウンロードされれば、後はダウンロードされたLLMを使うため、それぞれのLLMごとに1回だけダウンロードが発生します。
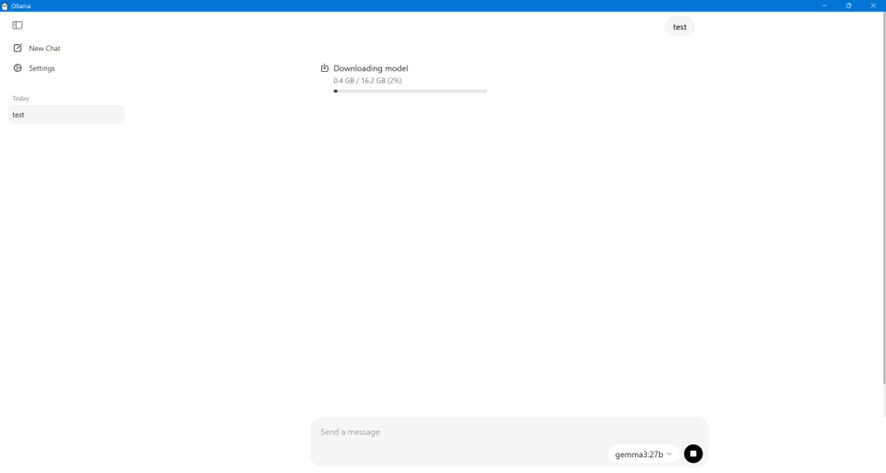
LLMですが、スペックを考慮せずにダウンロードされるため、実行しても動作しないこともあります。少なくとも当方のモバイルノートPCでGemma3:27bは動作しませんでした。C:\Users\<ユーザー名>\AppData\Local\Ollama内にログが作成されていますが、
time=2025-07-31T22:58:32.478+09:00 level=ERROR source=ui.go:988 msg="chat stream error" error="model requires more system memory (20.3 GiB) than is available (17.4 GiB)みたいにエラーが記録されます。どうもGemma3:27bでは20.3GiB以上の物理空きメモリが必要ですが、17.4GiBしか確保できなかったようです。この場合は、GUI画面でもエラーが表示されます(ただしエラー内容は分かりづらいです)。
今回動作させたモバイルノートPCでは32GBの物理メモリは積んでいますが、完全な空き容量としては20.3GiB無かったので、動作しなかったようです。
モデルが動作しない場合は、より小規模なパラメータ数(例:4bや8bなど)のLLMを試すとよいでしょう。今回のノートPC環境ではGemma:12bは問題なく動作しました。
GPUの利用
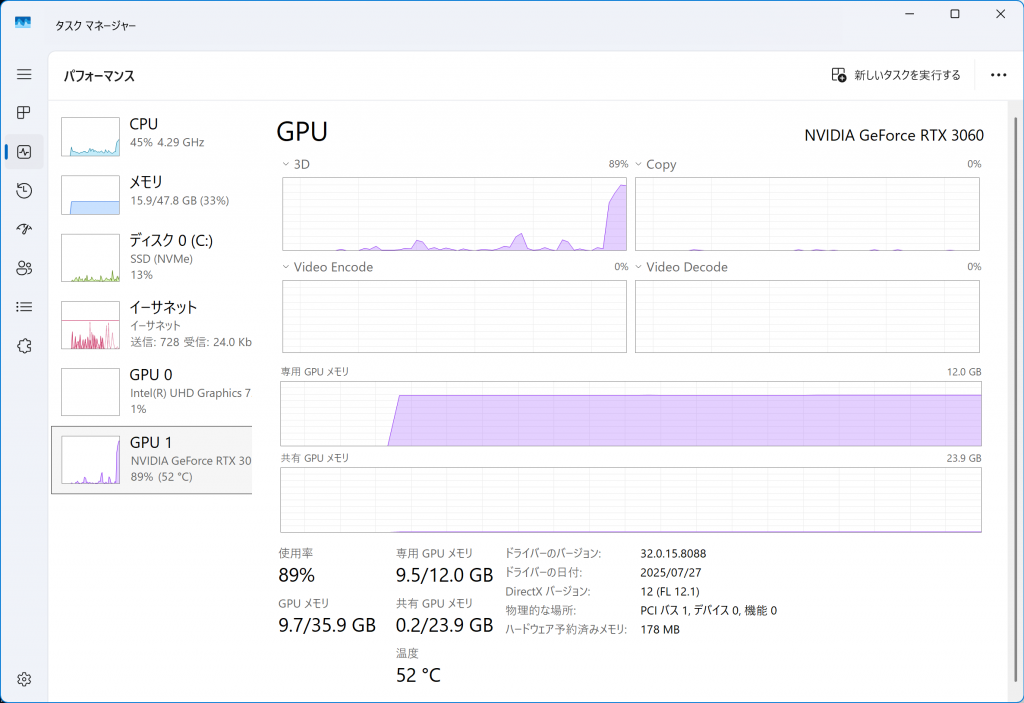
48GBの物理メモリ、12GBのGPUメモリ(Geforce 3060GTX)を搭載したマシンでも試しました。多くの場合、GPUの使用率は20〜30%程度にとどまり、CPUが主に利用されていました。Ollama Desktopでは、モデル全体がGPUメモリに収まる場合はGPUをフル活用し、GPUの使用率が100%近くまで使われます。それ以外はCPUやRAM主体で動作します(モデルや実行環境により挙動は異なる場合があります)。GPUメモリにモデル全体が載ってもそれなりの物理メモリは使うので(3GB程度)やはりメモリ依存なところはあります。今回は、NPUが載っていないマシンで扱ったため、載っているマシンだと多少挙動が変わるかもしれません。もっとも現状では限定的な対応に留まっているようなので、今後に期待したいところです。
まとめ
GUI化されたことで、日常使いには使いやすくなっています。他のOllamaでサポートされているLLMが使えるようになると、より精度の高いものも使えるため、利便性も向上しそうです。
現状では、モバイルノートPCで常用するのは難しいのも事実なので、外から使うときは、VPN接続でデスクトップに繋いで、利用するとかになるとは思います。
ただ、2~3年前では考えられなかった精度のLLMがローカルPCで動くようになっているという、恐ろしいスピードで進化している世界を垣間見られます。
CTO / sekiguchi
技術系の責任者。AIの利用やAIへのデータ投入など活用するものに興味が向いている。PHPなどを用いてバックエンド開発を行うほか、サーバーの管理、運用を行う。 専門学校や大学、他社でのウェビナーによる講義もしている。
